Core Concepts¶
YAAI has a small surface area. There are five things to understand, and they chain together linearly.
Models¶
A model represents a deployed ML system. "Fraud detector", "churn predictor", "price estimator" -- one entry per thing you want to monitor. It's just a name and a description.
Versions¶
A model version pins a specific input/output contract. When your model's features change -- new input field, different output format, removed a column -- create a new version. This keeps historical data and drift results clean: version v1.0 results are never mixed with v2.0 data.
Versions are cheap. Create them whenever the contract changes.
Schema¶
The schema is the core of YAAI. It's a list of fields that describes what your model takes in and what it produces:
From this, YAAI derives everything:
| What | How |
|---|---|
| Dashboards | numerical fields get histograms, categorical fields get bar charts |
| Validation | incoming inference data is checked against the schema |
| Drift metric | numerical defaults to PSI, categorical defaults to Chi-squared |
| Comparison charts | overlaid histograms for numerical, grouped bars for categorical |
You can define schemas manually or let YAAI infer them from a sample payload. Either way, the schema is the single configuration point. There is no other setup.
Note
Schema locking — You can freely edit a schema until the first drift detection job runs. After that, the schema is locked to protect historical results. To change the schema, create a new version.
Inference data¶
Inference data is what your model sees in production. Every time your model makes a prediction, send the inputs and outputs to YAAI:
{
"model_version_id": "...",
"inputs": {"age": 35, "income": 72000, "region": "west"},
"outputs": {"churn_prob": 0.73}
}
YAAI validates it against the schema, stores it as JSONB, and it immediately shows up in dashboards. Send data one at a time or in batches of up to 10,000.
Extra fields not in the schema are silently ignored -- this means your service can send more data than the schema defines without breaking anything.
Reference data¶
Reference data is the baseline -- typically your training set or a known-good sample. It represents what the model's input distribution should look like.
Upload it once per version:
Drift detection compares recent inference data against this baseline. Without reference data, you can still use rolling-window comparison (today vs. yesterday), but vs_reference mode needs a baseline to compare against.
Drift detection¶
Drift means the data your model sees has changed compared to what it was trained on. If your model was built for customers aged 20--50 and suddenly starts getting data for ages 60--80, that's drift. The model's predictions may no longer be reliable.
YAAI detects drift by comparing two distributions and measuring how different they are. Four metrics are supported:
| Metric | Data type | What it measures |
|---|---|---|
| PSI (Population Stability Index) | numerical | Bucket-by-bucket shift magnitude |
| KS test (Kolmogorov-Smirnov) | numerical | Maximum CDF distance, with p-value |
| Chi-squared | categorical | Frequency difference significance |
| Jensen-Shannon divergence | categorical | Symmetric distribution similarity |
Defaults: numerical fields use PSI, categorical fields use Chi-squared. You can override per field in the schema.
For a detailed walkthrough of how each metric works (with ASCII art and intuition), see the Drift Detection Guide.
Jobs¶
Drift detection runs on a schedule. A job defines:
- When to check -- cron expression (e.g.,
0 2 * * *for daily at 2am) - What to compare --
vs_reference(against your baseline) orrolling_window(against the previous period). Currently, each job supports only one comparison type; combining both in a single job config is not yet supported. - How much data to look at -- window size (e.g., "1 day", "7 days")
When you create a model version, YAAI creates a default job automatically (daily at 2am, comparing the last day of inferences against reference data). It activates when you upload reference data.
Each job run produces a drift result per schema field. If any field exceeds its threshold, a notification is created.
Comparison view¶
The comparison page is the interactive counterpart to automated drift jobs. Pick any two time ranges -- or compare inference data against reference data -- and see overlaid distributions for every field. Drift scores are computed inline.
This is useful for investigating shifts you've been alerted about or for ad-hoc exploration ("did anything change after last Tuesday's release?").
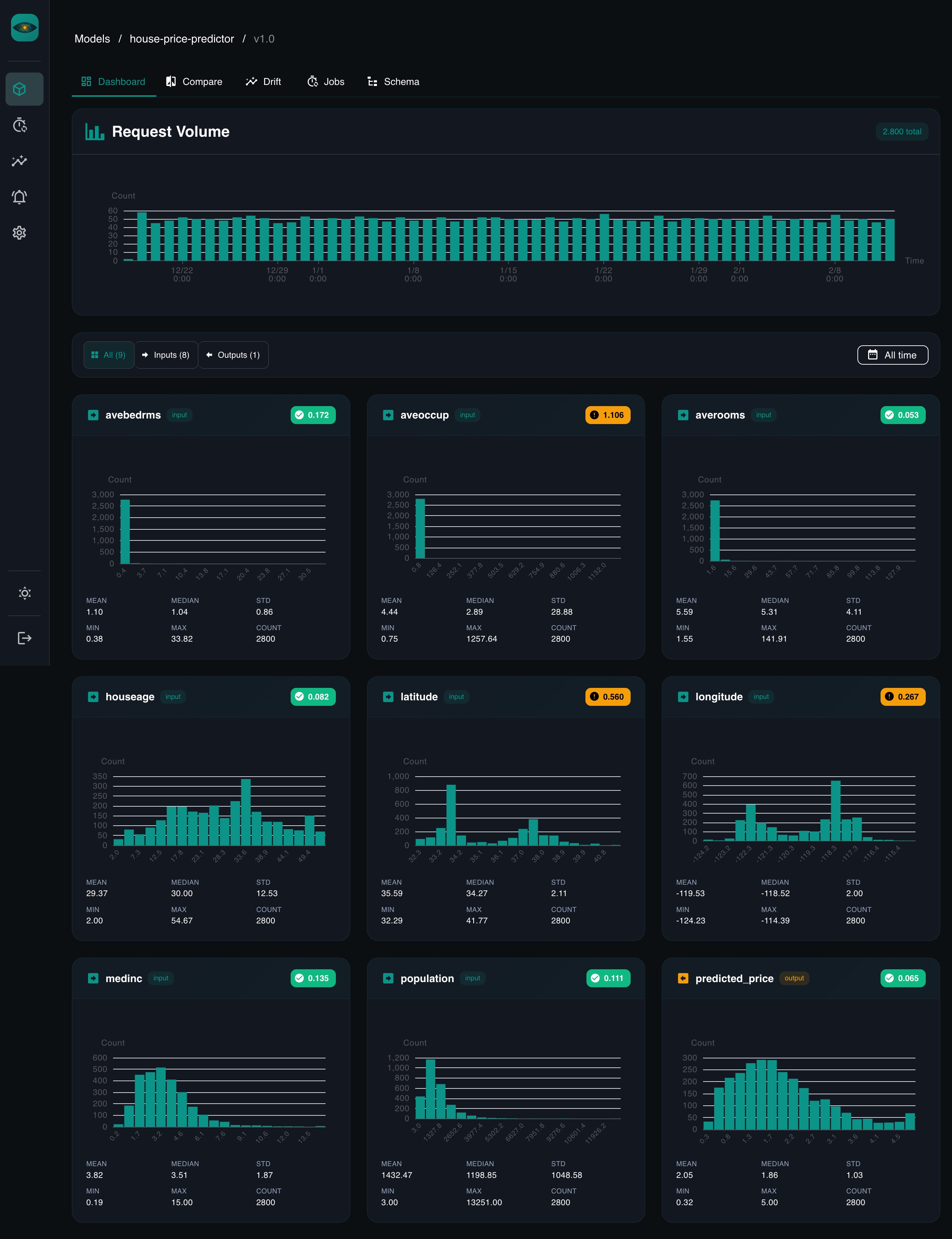
Auto-dashboards¶
There's no dashboard builder. When you navigate to a model version in the UI, YAAI queries inference data for every schema field and renders:
- Histograms for numerical fields, with mean, median, std, min, max
- Bar charts for categorical fields, sorted by frequency
- Drift badges showing the latest score per field
The time range is adjustable. Tabs filter by input vs. output fields.
Authentication¶
YAAI supports four auth methods:
- Local accounts -- username + password, enabled by default. An admin account is created on first startup with a randomly generated password (check the server logs). Owners can create additional users via the API. Public self-registration is disabled by default (
AUTH_LOCAL_ALLOW_REGISTRATION=false). - Google OAuth -- for human users via browser. Disabled by default. When enabled, local auth is automatically disabled.
- API keys -- for service accounts and SDK clients (
X-API-Key: yaam_...). Enabled by default. Keys are scoped per-model. - Google service accounts -- for GCP workloads using Application Default Credentials and ID token verification.
Two roles exist: owner (full admin access) and viewer (read-only).
Configure auth via environment variables (all prefixed with AUTH_). See the Server Setup guide for details.